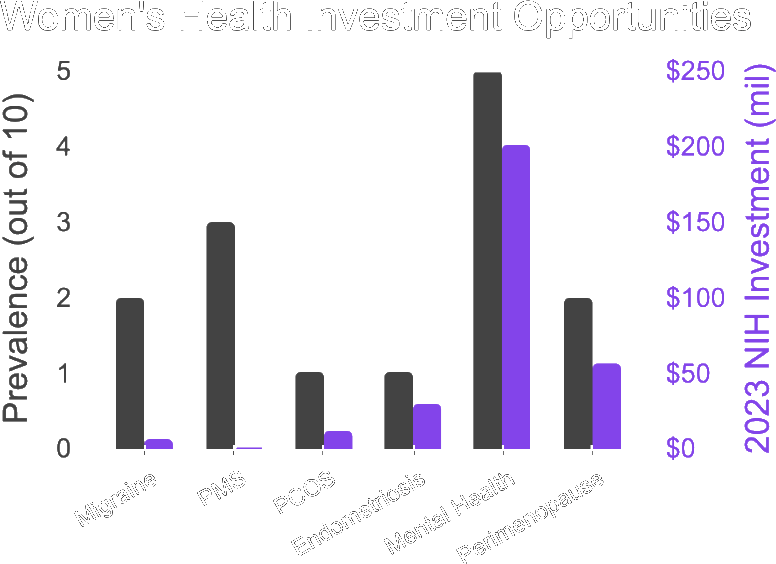
01
Understanding the human body: translating data into real knowledge
By
Maya & Ines Illipse
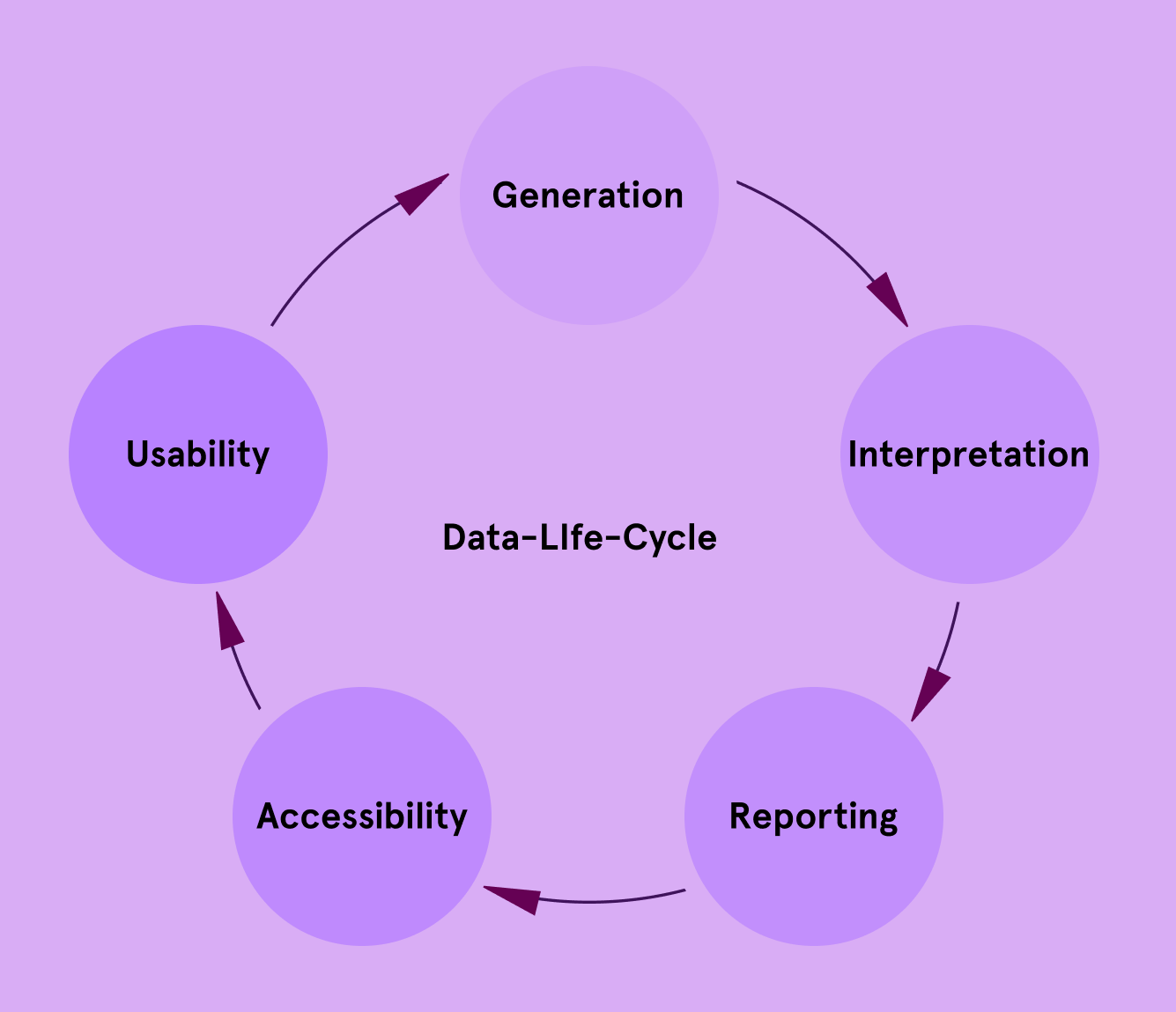
In today’s world, “data” is often treated like a magic word. The more data we have, the better decisions we can make, or so we are led to believe. But in reality, data alone is not insight. It is merely raw material. Like unprocessed ore mined from the ground, data requires refinement, context, and interpretation to become something useful.
Understanding what makes data meaningful is the first step toward using it responsibly and effectively, especially in health research.
What Is Data?
At its simplest, data refers to any collection of facts or measurements. In health, this can include:
Temporal trends
e.g., changes in mood over time
Unstructured content
e.g., free-text posts on health forums
Numbers
e.g., blood glucose levels, body temperature readings
Categorical information
e.g., diagnosis type, medication list
Different types of data capture different dimensions of health:
Each type brings a unique perspective. Together, they help researchers form a multi-dimensional view of human health.
Biological Data
Hormone levels, genetic tests, microbiome analysis
Behavioral Data
Sleep patterns, exercise routines, diet tracking
Self-reported Data
Symptom diaries, quality-of-life questionnaires
Social and Community Data
Online discussions on Reddit, patient support groups
Data ≠ Insight
Collecting data is just the beginning. Insight comes from understanding the patterns, causes, and meanings behind the numbers.
For example, a wearable device may record that a person’s heart rate spiked at 3:00 AM. Without context, this is just a number. Was it due to a nightmare? A fever? Sleep apnea? Anxiety? Without additional information, the raw data risks being misinterpreted.
Thus, context including the “who,” “when,” “where,” and “why” is essential. Good research designs pair data with rich metadata: time stamps, activity logs, demographic profiles, and environmental factors.
To be meaningful, data must meet several criteria:

Validity
To measure the intended concept
Eg. Blood pressure cuff calibrated correctly

Reliability
To produce consistent results
Eg. Same readings under same conditions

Completeness
To ensure no critical gaps or missing elements
Eg. Survey questions fully answered

Timeliness
To reflect current or relevant time frames
Eg. COVID-19 cases updated daily

Relevance
To pertain to the research question
Eg. Using glucose data when studying diabetes
Meaningful data tells a story that is true, clear, and applicable to the question at hand.
Data from New Frontiers: Community and Social Media



As digital platforms become central to how people discuss and manage their health, researchers have begun mining social media, especially Reddit, Twitter, and health forums, as sources of real-world, patient-generated data.
A well-known example is the identification of early long COVID symptoms on Reddit. Months before formal definitions were established, users were reporting cognitive issues, fatigue, and lingering respiratory problems. A 2021 analysis of over 40,000 Reddit posts showed that some self-reported symptoms were more common or entirely absent compared to initial clinical reports¹. This demonstrated the platform’s power as an early signal detection tool.
However, these findings must be treated with caution. To process large volumes of scraped content, researchers often rely on AI tools to extract symptoms automatically from user posts, a process known as automated symptom extraction. These systems scan text for mentions of health-related terms (like “headache” or “fatigue”) and try to map them to medical conditions. But social media posts are messy: people use slang, metaphors, or exaggerate for emphasis. As a result, the AI may misinterpret jokes, misspellings, or vague descriptions, leading to inaccurate or incomplete results.
Another challenge is that there is no clear way to clinically validate these symptoms. Because posts are anonymous and self-reported, researchers can’t check them against medical records or confirm whether a diagnosis or treatment followed. This means that while these early signals can highlight potential trends, they should not be treated as established clinical evidence.
Moreover, online communities reflect a biased subset of the population, often younger, more tech-literate, and from higher-income regions.
The lack of context is another major pitfall. Posts scraped from forums may omit critical metadata: age, medical history, or concurrent conditions. Without these, interpretations can be skewed. For example, a surge in reported anxiety could reflect a social trend, seasonal variation, or actual health events, but the data alone won’t reveal which.
Social data has shown promise in women’s health as well. Natural Language Processing (NLP) tools have been used to identify unreported side effects from breast cancer medications and trace emerging public concerns around menstruation or reproductive rights.² ³ Still, ethical concerns persist; even if posts are public, many users do not expect their words to be analyzed by researchers.
Researchers should use patient-generated data with caution. While scraped data can help formulate hypotheses, uncover lived experiences, and prompt more inclusive study designs, it must be interpreted carefully, contextualized rigorously, and supplemented with more robust sources.
Emerging Data Innovations: Synthetic Data and Federated Learning
To navigate the tensions between data privacy and access, researchers are turning to newer innovations like synthetic data and federated learning.
Synthetic data mimics real-world datasets by generating artificial records that follow similar statistical patterns. In women’s health, this has enabled the development of AI models while protecting sensitive data, such as pregnancy outcomes or rare disease profiles⁴.
But synthetic data comes with serious caveats. Due to it being generated from existing data, it can only reproduce patterns we already understand; it cannot reveal unknown correlations or detect new phenomena. Worse, if the source data is biased, synthetic outputs will amplify that bias, often invisibly. Also, because synthetic data is fabricated, it risks being misused or misunderstood as real evidence when not clearly labeled.
Federated learning, meanwhile, enables machine learning models to be trained across institutions, like hospitals, without moving patient data. In women’s health, it has been applied to conditions like polycystic ovary syndrome (PCOS), allowing privacy-preserving prediction models⁵.
This method offers strong privacy advantages, but it introduces technical tradeoffs. For example, models trained this way may be less accurate due to system incompatibilities, while researchers have less visibility into the data itself, which can hinder validation and bias correction.
Both synthetic data and federated learning reflect a shift toward privacy-respecting, inclusive data science. But their use must remain grounded in transparency, scientific rigor, and awareness of their conceptual limits.
The Importance of Methodology & Finding Meaning in Data
Even the highest-quality data can mislead if paired with poor methods. A strong research methodology, encompassing careful study design, data collection procedures, and analytical strategies, is what transforms raw data into reliable knowledge. Methodology ensures that findings are not the result of chance, bias, or noise, but are grounded in scientific rigor. Without it, data risks becoming a source of confusion rather than clarity.
Despite the enthusiasm surrounding data-driven health research, the journey from data to actionable insight is fraught with complications. Volume alone does not equal value and in many cases, more data can simply mean more noise, more bias, and more confusion.
Volume vs. Quality
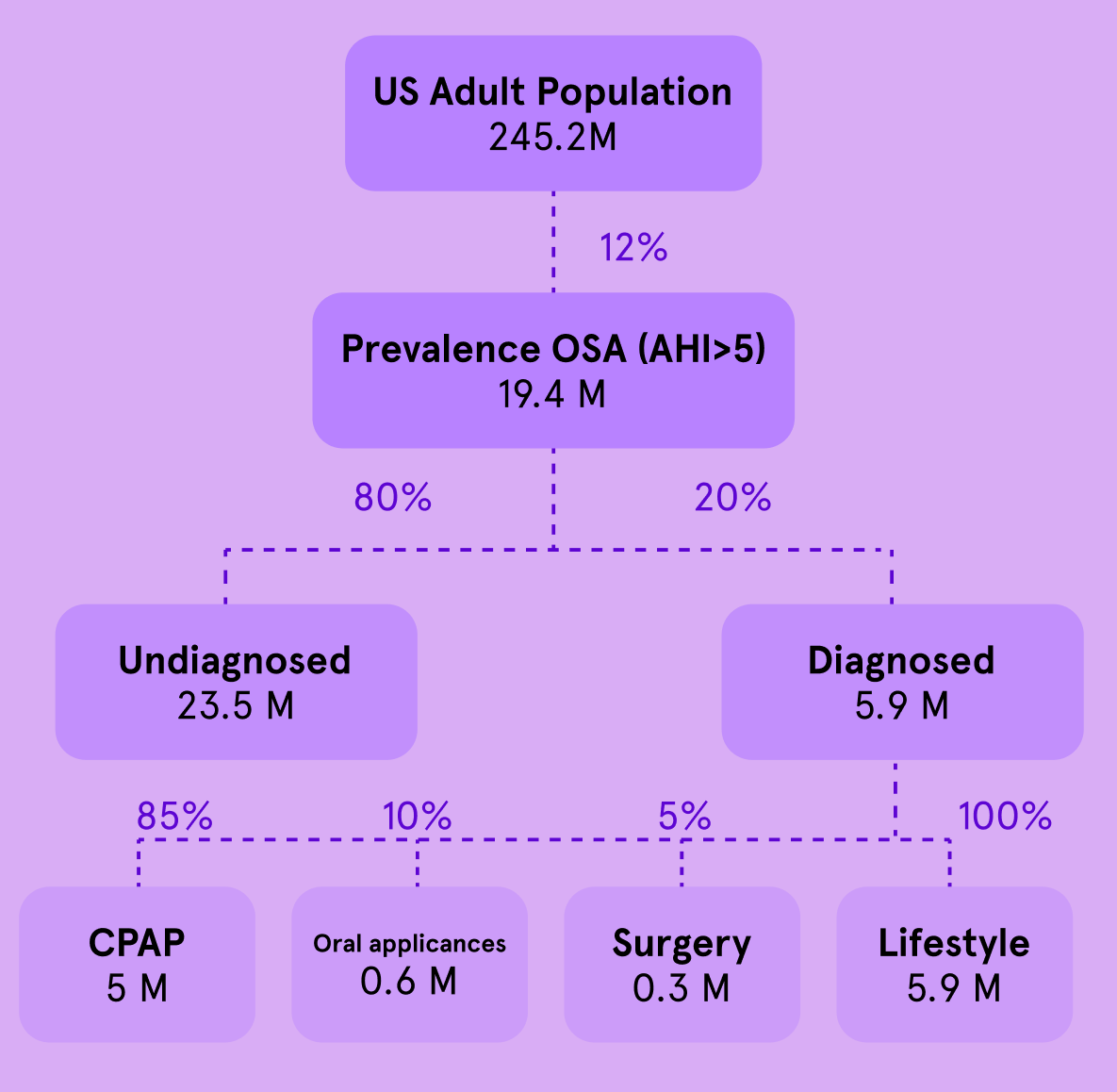
A million messy data points can be far less useful than a few carefully gathered ones. When Google's AI model for detecting diabetic retinopathy was deployed in clinics in Thailand, it encountered significant issues due to noisy datasets: blurry eye scans, missing metadata, and lack of standardization in data collection. The result? High false-positive rates and reduced trust among healthcare workers. The model’s impressive lab performance failed to translate into real-world impact, a stark reminder that without quality, big data is just big noise⁶.
Bias, in New and Old Forms
Bias remains one of the most insidious threats to meaningful data use. Sampling bias can arise when certain groups are over or underrepresented. Measurement bias creeps in when instruments don’t capture reality accurately. But in the age of AI, we now face model-level bias, too.
Large language models (LLMs), for instance, are increasingly used to summarize clinical records, support decision-making, or even generate patient communications. Yet studies show these models may reinforce gender or racial bias. One evaluation of LLMs in long-term care scenarios found that models like Gemma often downplayed women’s health concerns. Attempts to fine-tune models to reduce gender bias inadvertently introduced ethnic bias, a troubling trade-off that suggests quick fixes may not suffice⁷ ⁸.
Interpretability and the "Black Box" Problem
Advanced machine learning can uncover subtle patterns beyond human reach, but the complexity of these models introduces new risks. When a model provides a prediction, can we trace why? If not, how do we trust it, especially in critical health contexts?
In practice, opaque models can lead to decisions that are hard to question or validate. And when something goes wrong, as with Google Flu Trends, which vastly overestimated flu outbreaks due to search term fluctuations unrelated to illness, there’s little clarity about what failed or why⁹. The opacity undermines accountability.

The biggest challenge in data: Ethics & Ownership
In today’s world, our ability to collect data has outpaced our ability to make sense of it. From clinical biomarkers to online conversations, we are surrounded by signals, but the real challenge lies in distinguishing what is meaningful from what is merely noise.
This becomes apparent when thinking about the fraught landscape of wearable health monitoring devices. Health data is intensely personal. Yet, in a growing number of cases, it is treated as a commodity rather than a responsibility, making ethics and ownership a concern.
Wearables often operate in regulatory gray zones, where not only data ownership is unclear and informed consent is minimal, but also where commercial interests override patient control. As a result, rather than enabling agency, personal data becomes a liability exposing users to surveillance, discrimination, or manipulation.
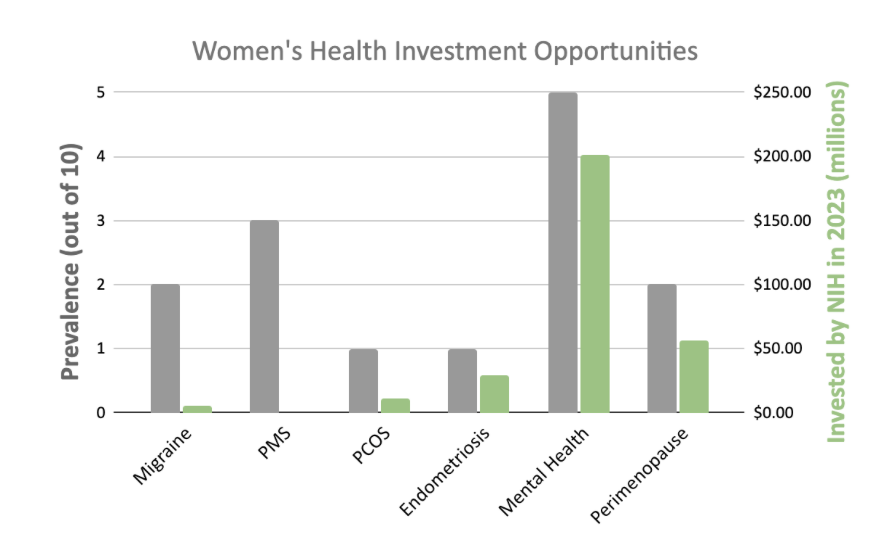
This erosion of trust is particularly problematic in women’s health, where historical gaps in care and underrepresentation already exist. If health technologies reinforce these inequalities rather than addressing them, they risk amplifying harm under the guise of innovation.
High-quality, well-contextualized data forms the foundation of progress in health research, but it is not enough on its own. Without scientific rigor, methodological care, and ethical responsibility, even the richest datasets can lead us astray. Data does not automatically equal insight; and insight does not automatically lead to real-world impact.
As we stand at the intersection between technology, biology, and society, the way we understand and use data will shape the future of healthcare. Approaching this information with both intellectual rigor and human sensitivity will be key to transforming numbers into knowledge, and knowledge into better health for all.